
Emacs のようなエディタはマイクロソフト Word のような WYSIWYG: What You See Is What You Get を是とするシステムと違い、素養があれば細かな制御が可能な文書編集環境として、技術者にとってはなくてはならないものです。本稿では、そうした Emacs のようなエディタでしか実現が困難な編集操作を取り上げます。
特に Emacs は文字エンコーディングのサポートの歴史が長く、半田剣一らの Mule (Multilingual Enhancement) Emacs の時代から極めて安心して多言語テキストの編集が可能となっています。
例えば、Emacs で M-x set-buffer-file-coding-system をエンターして、タブキーを押してみてください。するとサポートしている多種多様な文字エンコーディング方式が選べるようになっていることがわかります。実はいつの版の頃からか、サーポートしているすべての方式が通常のタブでは表示されない仕様になっていて、「i」キーを打ち込んでからタブキーや「w」キーを押してからタブキーを押してみると、加えてさらに多くの方式が選べます。ちなみに、M-x set-buffer-file-coding-system はカレントバッファのファイル文字エンコーディング方式を切り替えるコマンドです。
お助けとして見てみると、どこぞからコピペしたテキストで「-」のつもりが「−」になってたり、「'」のつもりが「’」になってたりする Unicode に対する勉強不足が原因であることが多いです。
Emacs なら、先の M-x set-buffer-file-coding-system をエンターして、euc-jp などとしてみましょう。そうすれば Unicode 特有の意図しない文字が見つかるはずです。意図しない文字を直したら文字エンコーディング方式を utf-8 に戻しておきましょう。
この例のように、Emacs はプログラミング環境としての価値以上に、文字エンコーディング方式の最強のサポート環境として、余人をもって代え難い孤高のソフトウェアであると認識すべきです。
さあ、その強力なエディタ環境で例示しないと語ることが難しい(けど興味深い)テーマを取り上げていきます。
本稿は Emacs のような「エディタ」が必要になる理由を解説するものですが、一つに Unicode のような「文字エンコーディング」への対応が特に Emacs は優れていることをあげます。そのためには、しばらくは Unicode の「絵文字」についての基礎知識についてお付き合いいただきます。
絵文字のほとんどは Unicode のコードポイント U+1F300 以降にありますが、実はそれだけでなく U+2600 辺りにもあります。この辺りに収納されている文字は Unicode 以前のマルチバイト文字の、例えば、JIS X 0213 の「♥」1-06-30 由来のコードポイント U+2665 ですし、「☀☁☂☃」1-06-72〜75 由来の U+2600〜2603 です。
しかし、処理系やフォントによっては、これらは「着色絵文字」のグリフが選ばれて「♥️」「☀️☁️☂️☃️」と表示されてしまいます。手元でそれに気づけば幸いですが、何か相手に伝わってから意図しない着色絵文字になっていたとしたら、表題のように「白黒のハートのつもりだったのに、真っ赤なハートになってしまい、ちょっと恥ずかしい思いをした」ということになりかねません。例えば、技術文書などお堅い文書で意図せず着色絵文字になっていてボスに「これは何だ」とお叱りを受けてしまうかもしれません。
このように、状況によっては着色絵文字になってしまう「絵文字」に関する「Unicode の規格」について知っておく必要があります。
逆のケースもあり得ます。ハートには数種の色分けされたグリフがあり、意図してそれらを使用したい場合があります。
「❤️🧡💛💚💙💜🖤🤍🤎」、これは意図して着色絵文字にしています。
「❤︎🧡︎💛︎💚︎💙︎💜︎🖤︎🤍︎🤎︎」、これは意図して白黒絵文字にしています。この文書の閲覧環境によっては私が意図した通りには表示されていない可能性があります。
もし、着色されていることを前提に話を進めているのに意図せず白黒になってしまっていたら、全く意味が相手に伝わらないこと必至です。
本稿は Emacs のようなエディタを使いこなす技術者向けなのですが、そうではない読者はこの時点で不安になることでしょう。一先ず、そのような初心者が気をつけることができる事項をまとめておきます。
よって、Emacs に興味がない方でも以下の知識は必ずや役立つときが来るでしょう。
マイクロソフト Word のような処理系の場合、作業している見た目の通りに文書が作れるでしょうから、もし意図しないケースに備えてフォントに関する知識があればよいと思います。次のフォントがマイクロソフト Windows に搭載されている着色絵文字対応と、不足しがちなフリーの白黒絵文字対応になります。
それでもグリフが不足しがちなので、必要なら次に紹介するフリーの絵文字対応フォントを別途インストールするのもよいでしょう。
macOS の場合はたいへん充実した着色絵文字フォントが完備していますが、白黒絵文字対応フォントはやはり整備されていないようです。
それでもグリフが不足しがちなので、必要なら次に紹介するフリーの絵文字対応フォントを別途インストールするのもよいでしょう。
Google のオープンソース絵文字フォントがインストールされていないのなら整備しておくとよいでしょう。
白黒と着色の両方のフォントがあります。執筆時点で、Windows に対応した版の着色絵文字フォントが別ファイルで提供されています。
さらに、Twitter Color Emoji がオープンソースで公開されていました。フラットデザインで統一されていて印刷しても違和感がない印象です。
(注) TwitterColorEmoji-SVGinOT-MacOS-13.1.0.zip は Apple Color Emoji と共存不可、その置き換え目的なので、機種名(-MacOS)なしの書庫が宜しいようです。
着色絵文字はモバイルで必要とされることから普及していますが、紙媒体への印刷向けにやはり白黒絵文字フォントも準備をしておきたいものです。以下が Windows や macOS においても、有用な選択肢となり得ます。
ちなみに、後者のフォント配布サイトは Unicode.org のページでフォント指定されている事実から辿り着いたのですが、いささか成果が古いので GNU プロジェクトの成果物の方をお勧めします。いずれにしてもアップル、マイクロソフト、グーグル製よりは品質は劣りますので補助的に利用しましょう。
いよいよ Emacs のようなエディタの出番となります。マイクロソフト Word のような初心者向けの処理系だと IME 等入力ソース任せの領域になってしまい、以下で実現できることが制御不能となりがちです。
細かな制御が可能なエディタなら、やっていることは簡単です。異体字セレクタを文字コードの後ろに付加すれば、着色絵文字にするか、白黒絵文字にするか選べるようになるのです。絵文字を制御する異体字セレクタによる並びは、標準化された異体字シーケンス (SVS: Standardized Variation Sequence) の VS15 (白黒, U+FE0E), VS16 (着色, U+FE0F) を使います。
U+2665) の後ろに VS15 (白黒, U+FE0E) を付記 …「♥︎」U+2665) の後ろに VS16 (着色, U+FE0F) を付記 …「♥️」さて、この文書はウェブ向けに HTML で執筆しているので、Emacs 上での編集の様子は以下のようになります (スクリーンショットをクリックすると拡大)。
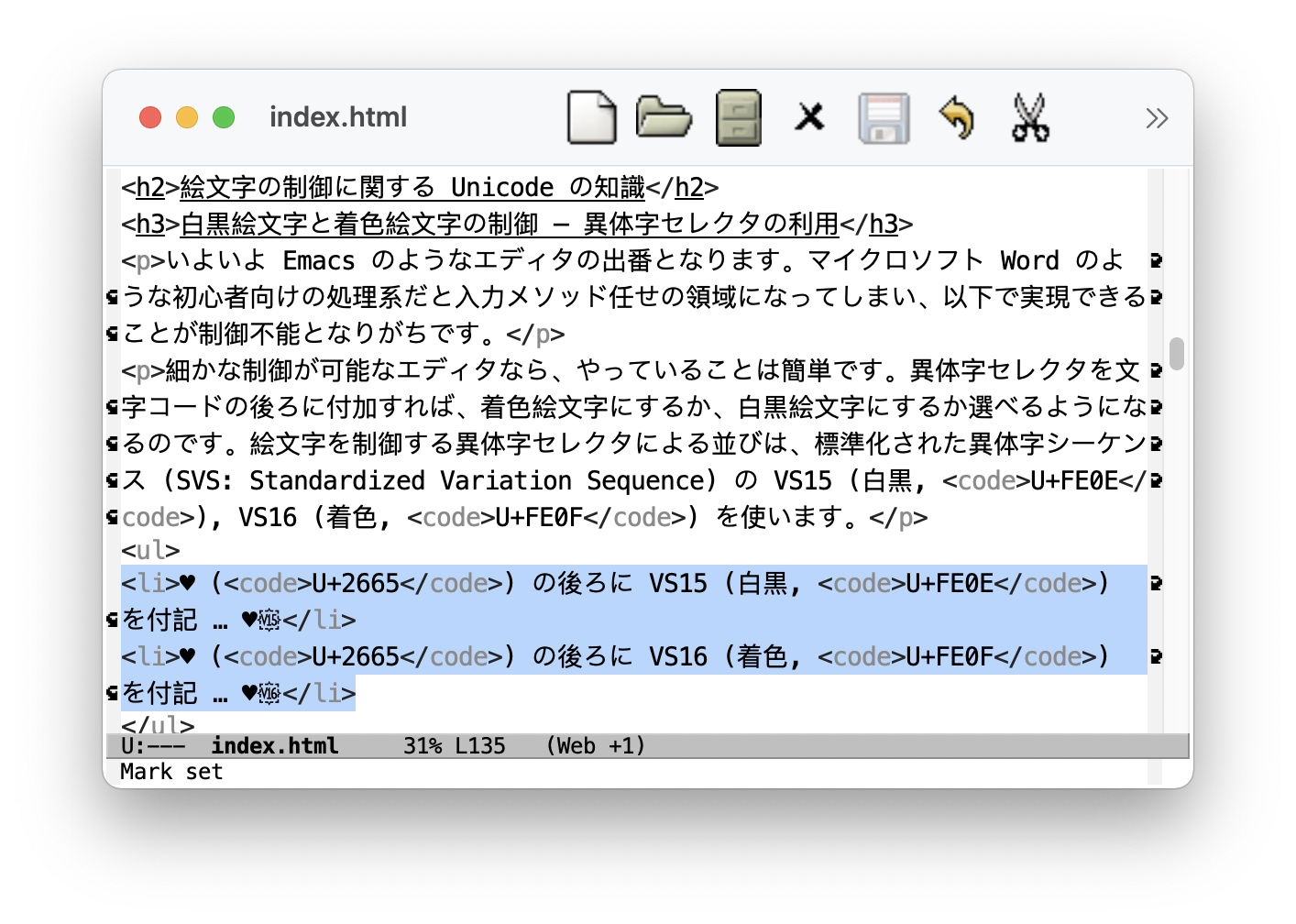
少し判別しづらいですが、この Emacs のスクリーンショットをみれば「V15, V16」と銘打たれたグリフが白黒絵文字の後に添えられていることが分かります。つまり、Emacs のようなエディタであれば技術者が細かく Unicode を制御できるのです。
念の為、ブラウザでは閲覧者によって見え方が異なるので、それを想定した表を作成しておきましょう。選択したグリフはほんの一部ですが、Unicode のコードポイント U+1F300 未満のグリフのうち、着色されていることが一部には違和感がありそうなものを選んでいます。そして、グリフがなかった場合には「⊠」が印字されるように設定はしてあります。
| Google 系フォント | Apple + フリーフォント | Microsoft + フリーフォント | フリーフォント | ブラウザ | |
|---|---|---|---|---|---|
| 白黒(SVS無) | |||||
| 白黒(SVS有) | |||||
| 着色(SVS無) | |||||
| 着色(SVS有) |
これを筆者の閲覧環境で見て言える結論をまとめておきます。
Segoe UI Emoji についてさらに加筆すれば、宗教や国家などの対立(次節の国旗など)の問題になりそうな絵文字は未サポートにする意思が感じられます。一方で Google や Apple のモバイルに慣れた人々にとっては不便に感じられるでしょう。
囲み英数文字 U+2460〜24FF には、日本でかつて「機種依存文字」などと忌避された、正確にはマイクロソフト・NEC・IBM らによる規格に則らない所謂 Shift_JIS エンコーディング方式による独自の CP932 で使われていた「ⅰ〜ⅹ, Ⅰ〜Ⅹ, ①〜⑳, ㌔, ㎞, №, ㈱, ㏍, ㍼」などが割り当てられています。
さらに、囲み英数文字追加 U+1F100〜1F1FF には「🄰〜🅉」などに加えて、日本の電波産業会による ARIB 外字「🅊🅌🅎…」「🆛🆞🆟🆠🆡🆣🆤…」などが割り当てられています。
この「囲み英数文字追加」の中に特殊な「囲みラテン文字」があります。「🇦〜🇿」がそれらです。実はこれらの2文字で ISO 3166-1 Alpha-2 国別コードを並べると「国旗の着色絵文字」になります。2文字のアルファベット 262 = 676 の組み合わせとなりますが、全て印字してみましょう。以下の表のようになります(すべての組み合わせなので、次に閲覧したときは増減しているかもしれません)。
例えば、行と列が「🇯」と「🇵」で交差するセルは「🇯🇵」となっていると思われます。つまり、Alpha-2 国別コードが定義された組み合わせならば国旗の絵文字で閲覧できているはずです。但し、Windows で Segoe UI Emoji しか絵文字フォントがないならば国旗は印字されないと思います。
このように、マイクロソフトは国家間のトラブルに発展しそうな規格には与しない、というより、実はこの組み合わせは「リージョンコードを表現する」だけで「国旗」として定義されているわけではないのです。しかし、元を正せば、絵文字の起源となった日本の携帯電話の絵文字に一部の国旗が定義されていたことで Unicode への導入となったわけですから、モバイル間の相互運用性を担保するには国旗を定義するしかないので、グーグルとアップルにより事実上、国旗としての絵文字がグリフに定義されています。
ちなみに、2文字のアルファベットの組み合わせだけでなく「🏴🏴🏴」のイングランド、スコットランド、ウェールズのような地域旗については、さらに特殊なラテン文字 U+E0061〜E007A のタグを使用して実現されています。よって、上の表にはこれらは表示されていません。この詳述は省略します。
さて、この話題を編集しているときの HTML ソースの一部の Emacs での様子をみてみましょう (スクリーンショットをクリックすると拡大)。ここで述べたアルファベットの組み合わせをそのまま記述している様子がわかると思います。
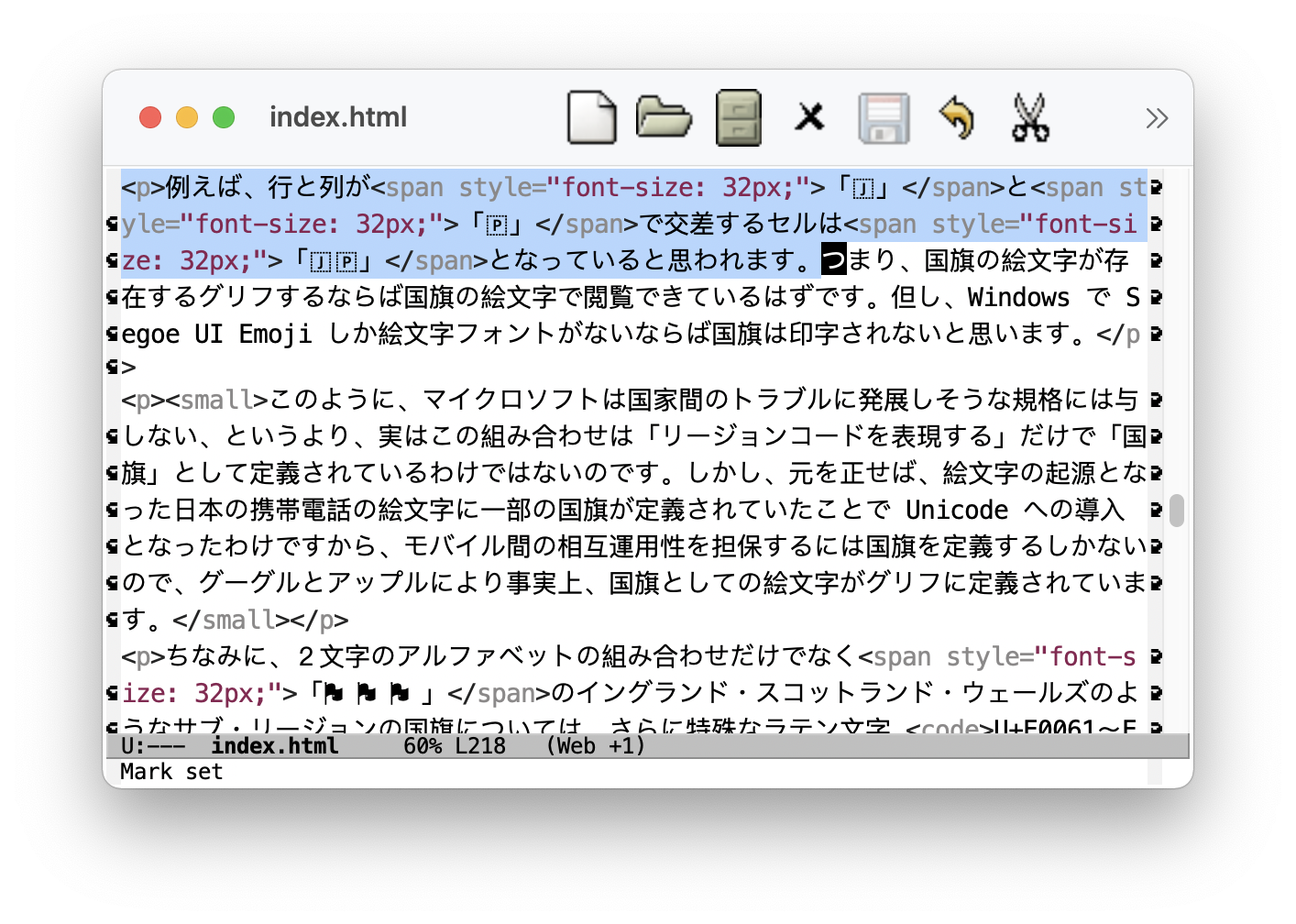
地域旗の編集については少々編集しやすくなる工夫が、まだなされていないようです(Emacs スクリーンショット下部の「🏴」の後ろにタグの特殊な囲みラテン文字「〜」列が実はたくさんあります。Emacs は少なくともそれを読めるようにすべきです)。
絵文字に限らないのですが、Unicode には合字の仕組みがあって、ラテン文字と合成可能な「ダイアクリティカルマーク」ですと、例えば「A」の後ろに「`」(グレイヴ・アクセント) の合成可能版 U+0300 (ここで直接書いてしまうと合成されてしまうのでコードポイントのみ) を付記すると「À」のように合字が作成できます。もっとも、合字されたグリフも「À」U+00C0 に既に用意されているものですから冗長です。ちなみに、こうした同義なものがいくつもの方法で表してあることはセキュリティ上好ましくはありませんので「Unicode 正規化」しておくことが推奨されています。
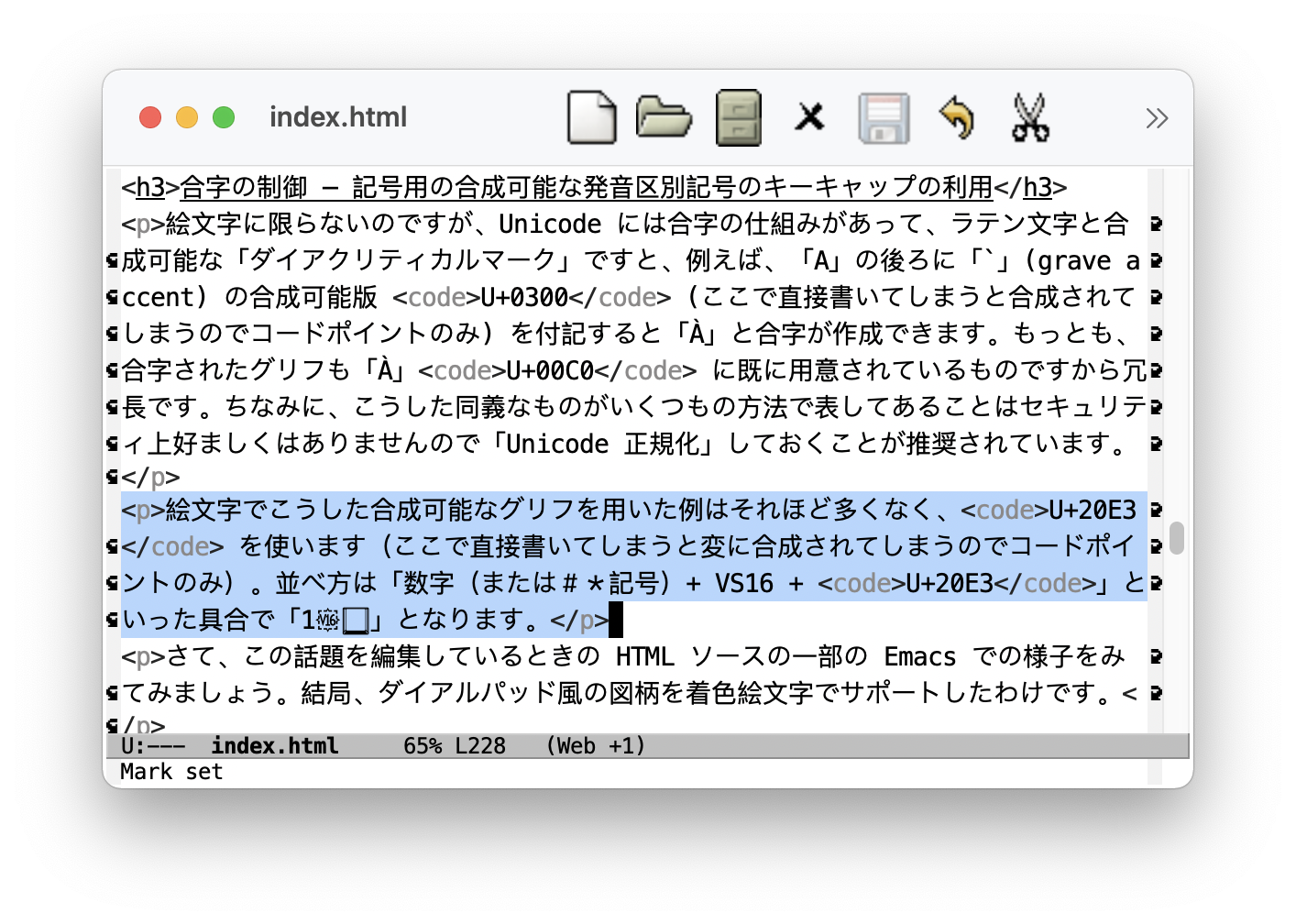
絵文字でこうした合成可能なグリフを用いた例はそれほど多くなく、U+20E3 を使います(ここで直接書いてしまうと変に合成されてしまうのでコードポイントのみ)。並べ方は「数字(または#*記号)+ VS16 + U+20E3」といった具合で「1️⃣」となります。
さて、この話題を編集しているときの HTML ソースの一部の Emacs での様子をみてみましょう (スクリーンショットをクリックすると拡大)。結局、ダイアルパッド風の図柄を着色絵文字でサポートしたわけです。
一応、Javascript による表の自動生成ですべての組み合わせを印字しておきます。
よくもまあ、U+20E3 (Combining Enclosing Keycap) などというグリフが合ったものです。このエリアには他にも囲み丸や囲み角などがあります。見た目で合成されるかどうかは処理系に依存します。
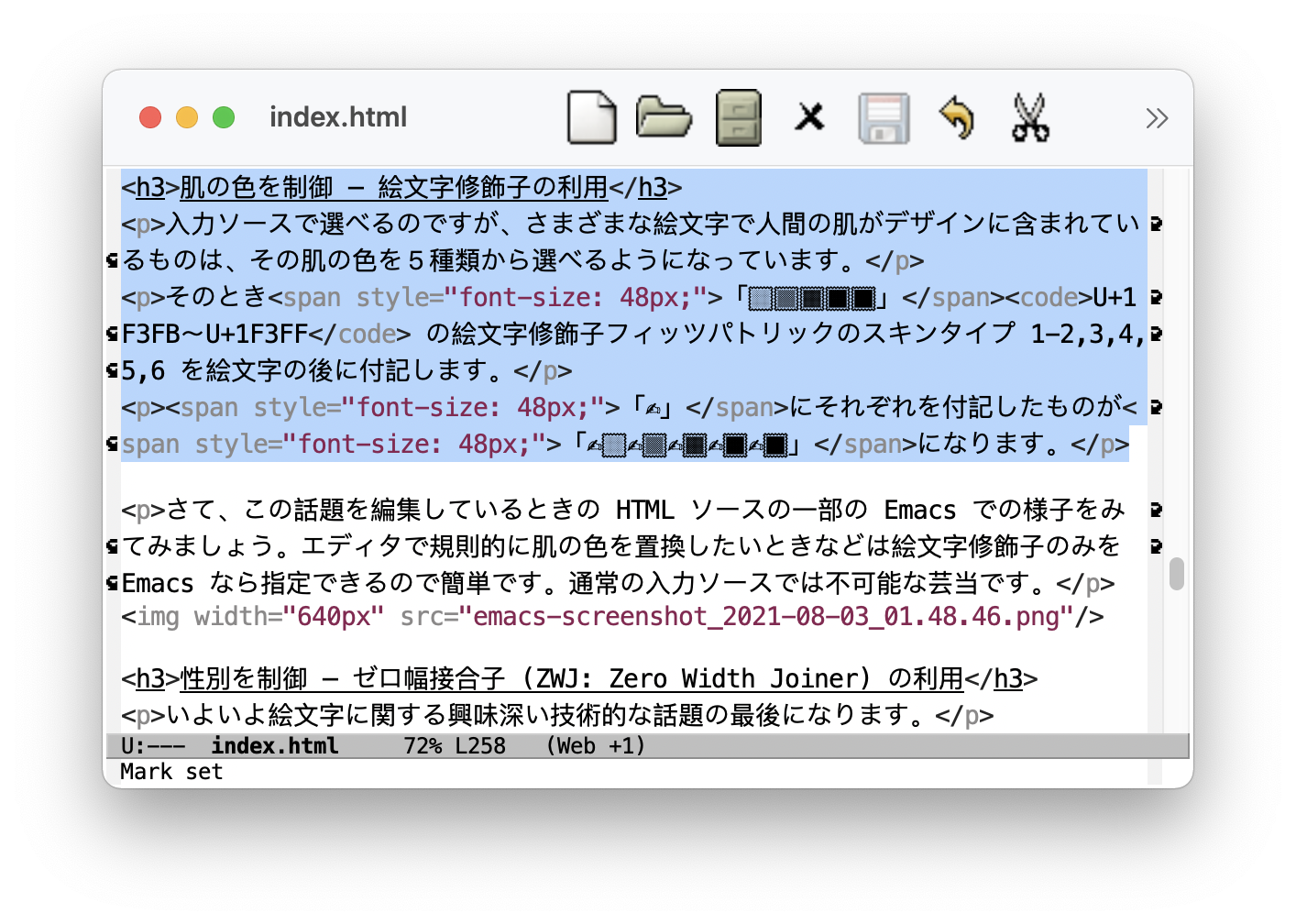
入力ソースで選べるはずですが、さまざまな絵文字で人間の肌がデザインに含まれているものは、その肌の色を5種類から選べるようになっています。
そのとき「🏻🏼🏽🏾🏿」U+1F3FB〜U+1F3FF の絵文字修飾子フィッツパトリックのスキンタイプ 1-2,3,4,5,6 を絵文字の後に付記されます。閲覧環境によっては、これらスキンタイプの絵文字単体では可視化されてないかもしれません。
「✍️」にそれぞれスキンタイプを付記したものが「✍🏻✍🏼✍🏽✍🏾✍🏿」になります。
さて、この話題を編集しているときの HTML ソースの一部の Emacs での様子をみてみましょう (スクリーンショットをクリックすると拡大)。エディタで規則的に肌の色を置換したいときなどは絵文字修飾子のみを Emacs なら指定できるので簡単です。通常の入力ソースでは不可能な芸当です。
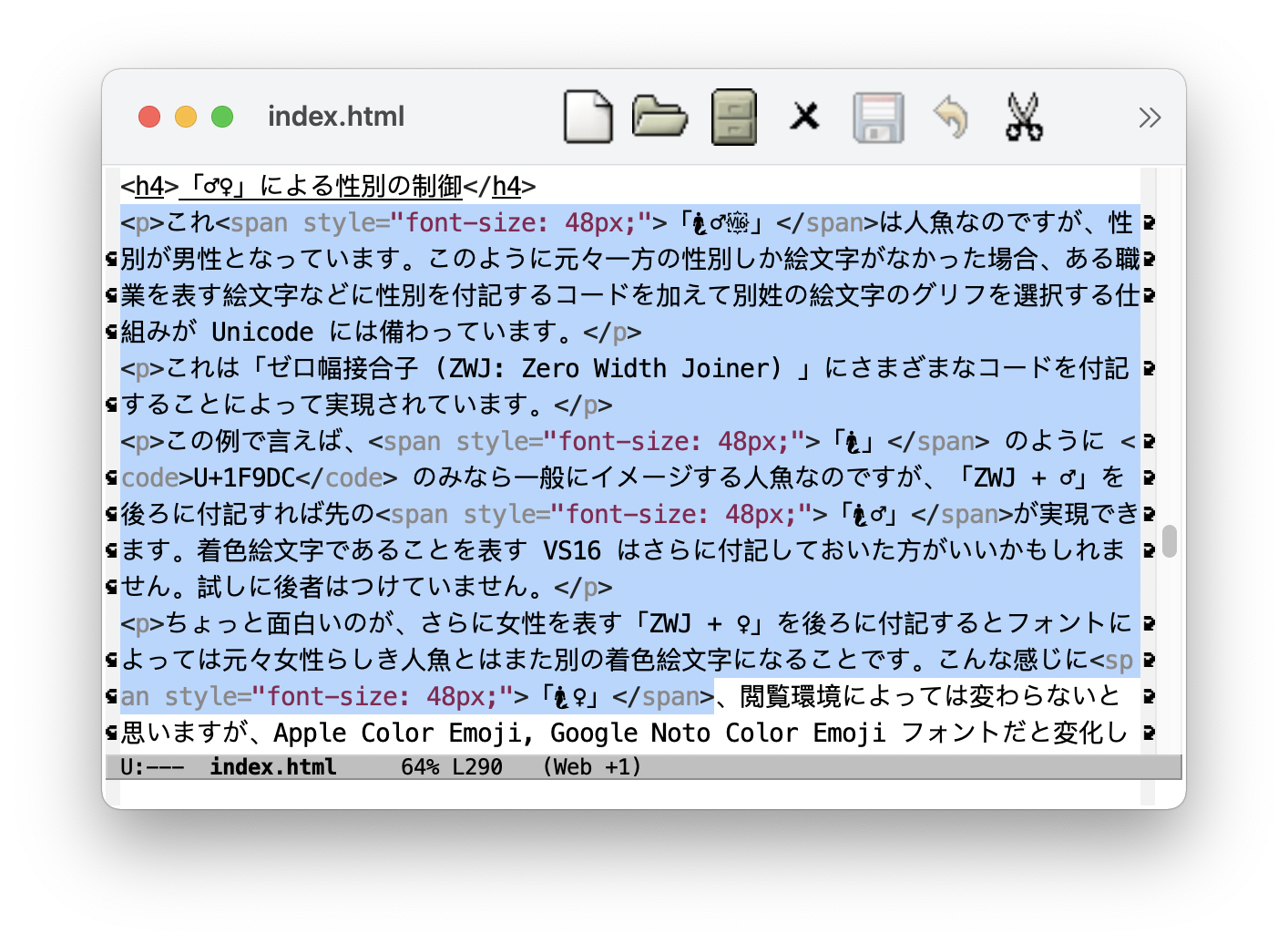
これ「🧜♂️」は人魚なのですが、性別が男性となっています。このように元々一方の性別しか絵文字がなかった場合、職業や競技を表す絵文字などに性別を付記するコードを加えて別姓の絵文字のグリフを選択する仕組みが Unicode には備わっています。
これは「ゼロ幅接合子 (ZWJ: Zero Width Joiner) 」にさまざまなコードを付記することによって実現されています。
この例で言えば、「🧜」 のように U+1F9DC のみなら一般にイメージする人魚なのですが、「ZWJ + ♂」を後ろに付記すれば先の「🧜♂」が実現できます。着色絵文字であることを表す VS16 はさらに付記しておいた方がいいかもしれません。試しに後者はつけていません。
ちょっと面白いのが、さらに女性を表す「ZWJ + ♀」を後ろに付記するとフォントによっては元々の人魚とはまた別の明らかに女性の着色絵文字になることです。こんな感じに「🧜♀」、閲覧環境によっては変わらないかもしれませんが、Apple Color Emoji, Google Noto Color Emoji フォントだと変化します。元々の人魚では「ジェンダー・ニュートラル」が配慮されているのです。
さて、この文書はウェブ向けに HTML で執筆しているので、Emacs 上での編集の様子は以下のようになります (スクリーンショットをクリックすると拡大)。
このような性別ごとにグリフのデザインが用意されたものは数多くあり、ここでとても網羅できないので、一部典型的なもののみ、そのままのもの、男性を明示したもの、女性を明示したもの、を表にしておきます。
これらに加えて、先の肌の色も制御できる「🧜♀🧜🏻♀🧜🏼♀🧜🏽♀🧜🏾♀🧜🏿♀」(ZWJ の直前にスキンタイプを挿入) ことから、非常に多くの着色絵文字が定義されていることがわかるかと思います。
ちなみに表中の「⚥」記号は ZWJ とは無関係で「ジェンダー・ニュートラル」をここでは意図していますが、必ずしも絵文字のデザインにそれが表れているかはフォント次第で、少なくとも Apple, Google の絵文字にはその意図が感じられます。日本の携帯電話の絵文字で元から男性・女性の両方が定義されていた「🕺💃」のジェンダー・ニュートラルは執筆時点ではまだ存在しないようです。
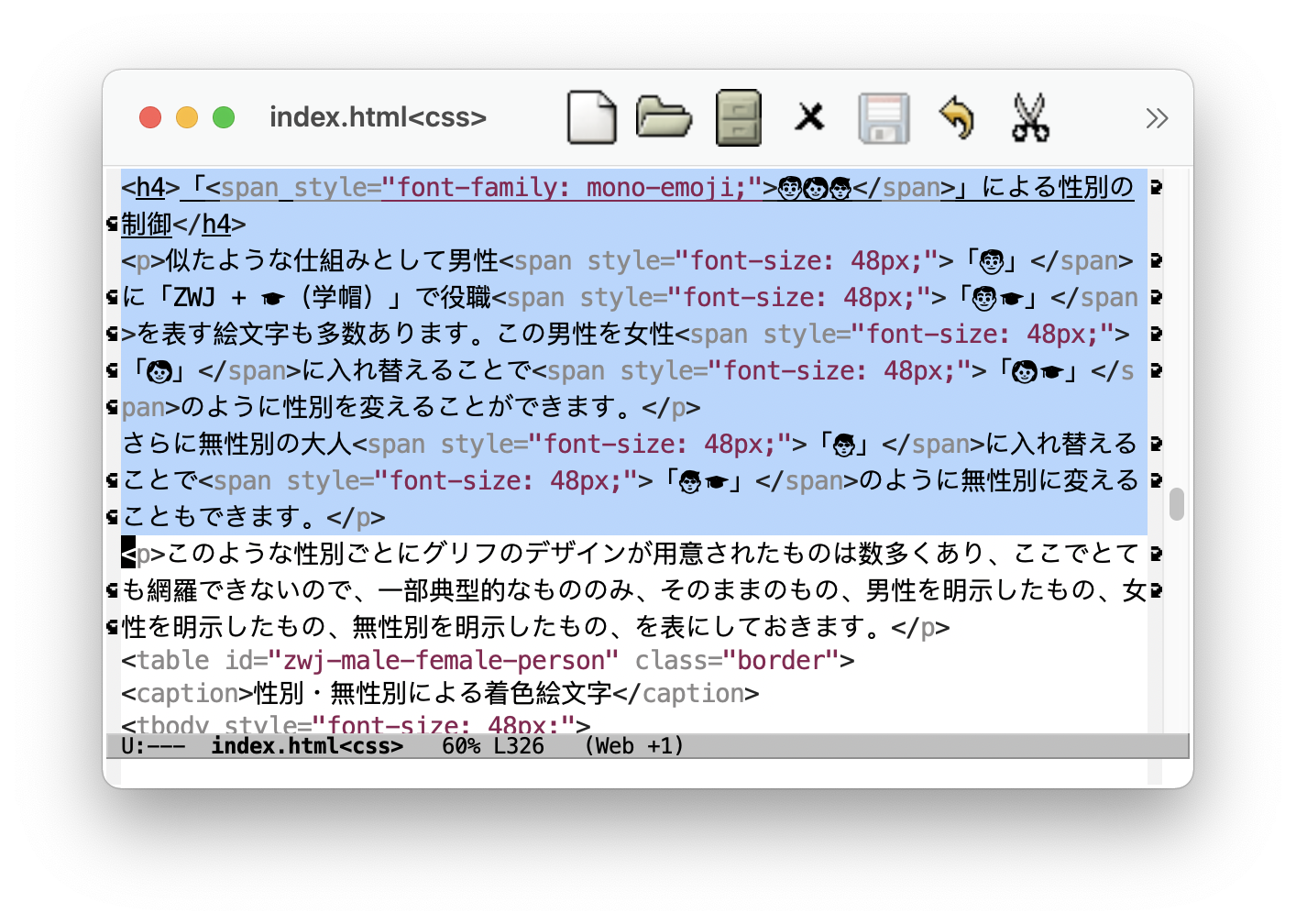
似たような仕組みとして男性「👨」に「ZWJ + 🎓(学帽)」で役職「👨🎓」を表す絵文字も多数あります。この男性を女性「👩」に入れ替えることで「👩🎓」のように性別を変えることができます。
さらに無性別の大人「🧑」に入れ替えることで「🧑🎓」のように無性別に変えることもできます。
このような性別ごとにグリフのデザインが用意されたものは数多くあり、ここでとても網羅できないので、一部典型的なもののみ、男性を明示したもの、女性を明示したもの、無性別を明示したもの、を表にしておきます。
これらに加えて、先の肌の色も制御できる「🧑🔬🧑🏻🔬🧑🏼🔬🧑🏽🔬🧑🏾🔬🧑🏿🔬」(ZWJ の直前にスキンタイプを挿入) ことから、非常に多くの着色絵文字が定義されていることがわかるかと思います。
さて、この文書はウェブ向けに HTML で執筆しているので、Emacs 上での編集の様子は以下のようになります (スクリーンショットをクリックすると拡大)。
Emacs 上で ZWJ はやはりほぼ不可視になってしまっていますが、カーソルを動かせばその存在はわかります。
ちなみに、妊婦と母乳を乳児にあげる女性「🤰🤱」は、流石に(アーノルド・シュワルツェネッガー扮するアレックス博士のような)男性や無性別は定義されていないようです(将来定義されたとて驚きません)。また、王子と王女「🤴👸」のような性別ありきの絵文字には無性別は定義されてませんし、忍者「🥷」のようなデザイン上、性別が識別できないものは男性と女性は未定義です。
無性別の大人「🧑」に「ZWJ + 🦳(白髪)」を付記することで「🧑🦳」のように、この大人の「髪型」を変えることができます。
さて、この文書はウェブ向けに HTML で執筆しているので、Emacs 上での編集の様子は以下のようになります (スクリーンショットをクリックすると拡大)。
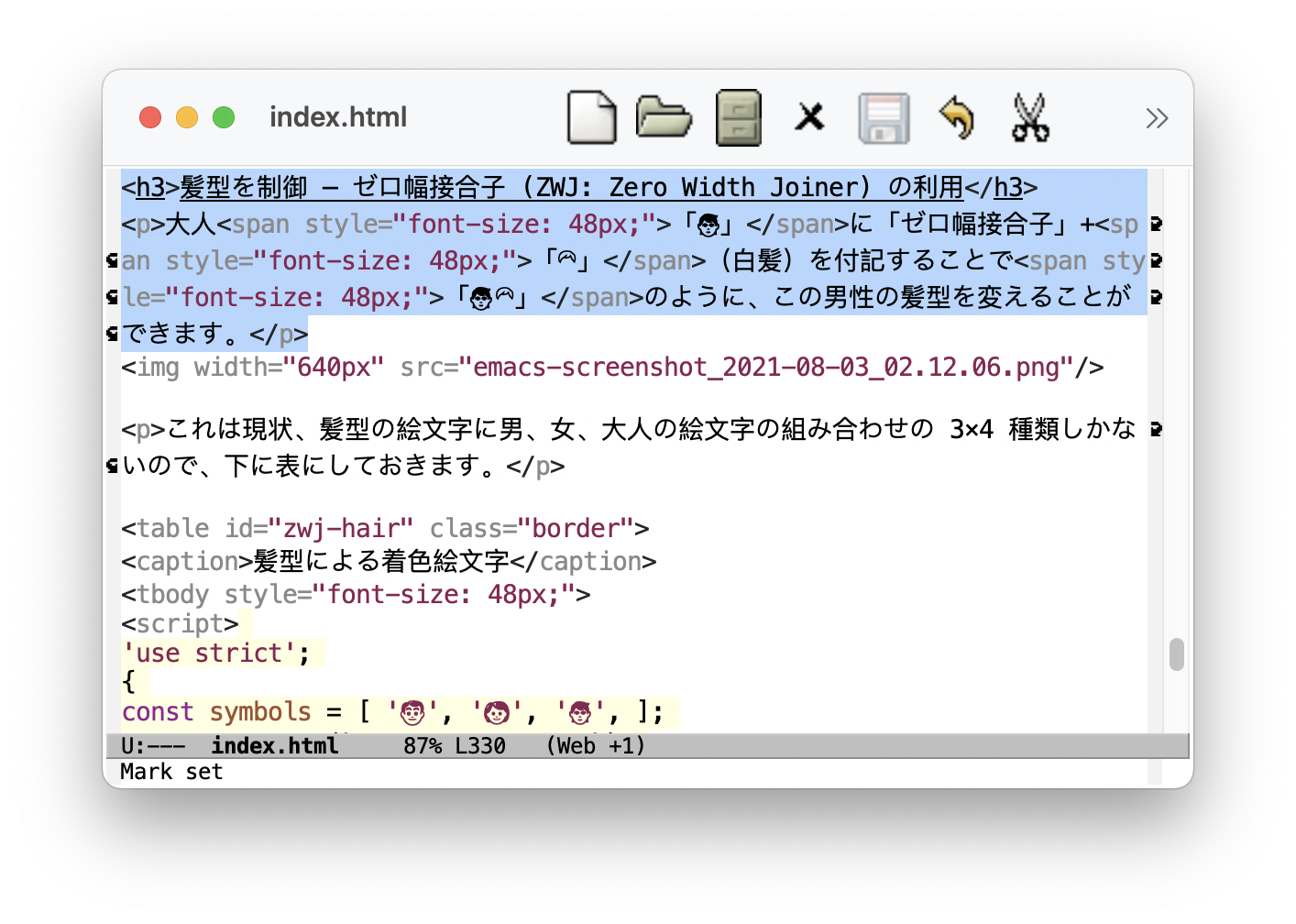
これは現状、髪型の絵文字に男性、女性、無性別の絵文字の組み合わせの 3×4 種類しかないので、下に表にしておきます。
髪型を添えているのに髭まで生える理由については分かりません。着色絵文字のデザイン次第です。
これらに加えて、先の肌の色も制御できる「👩🦳👩🏻🦳👩🏼🦳👩🏽🦳👩🏾🦳👩🏿🦳」(ZWJ の直前にスキンタイプを挿入) ことから、非常に多くの着色絵文字が定義されていることがわかるかと思います。
この髪型のみを絵文字として入力することは、入力ソースによっては難しいかもしれません。Unicode の U+1F9B0〜1F9B3 にありますので直接指定するとよいと思います。
少々技術的な話題となりますが、この Javascript による表の自動生成コードを以下に載せておきます (スクリーンショットをクリックすると拡大)。
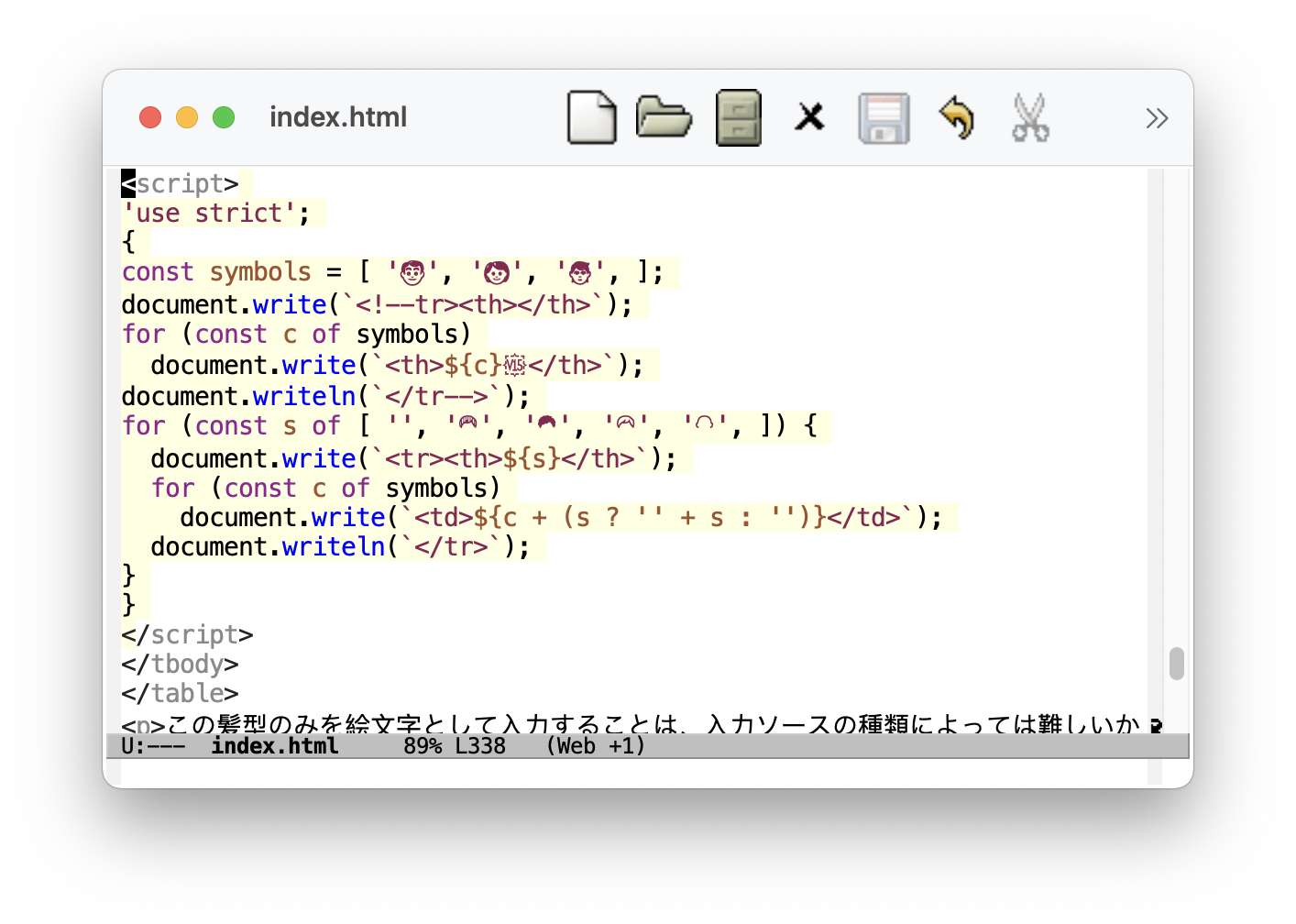
髪型の絵文字の配列と男性、女性、無性別の配列をそれぞれ結合して 4×3 の表になっています。
この「👨👩👧👦」メンバーで家族構成を表す絵文字を表すことができます。例えば、母の一人親で娘が2人「👩👧👧」を ZWJ で区切ると「👩👧👧」のようになります。
さて、この話題を編集しているときの HTML ソースの一部をみてみましょう (スクリーンショットをクリックすると拡大)。
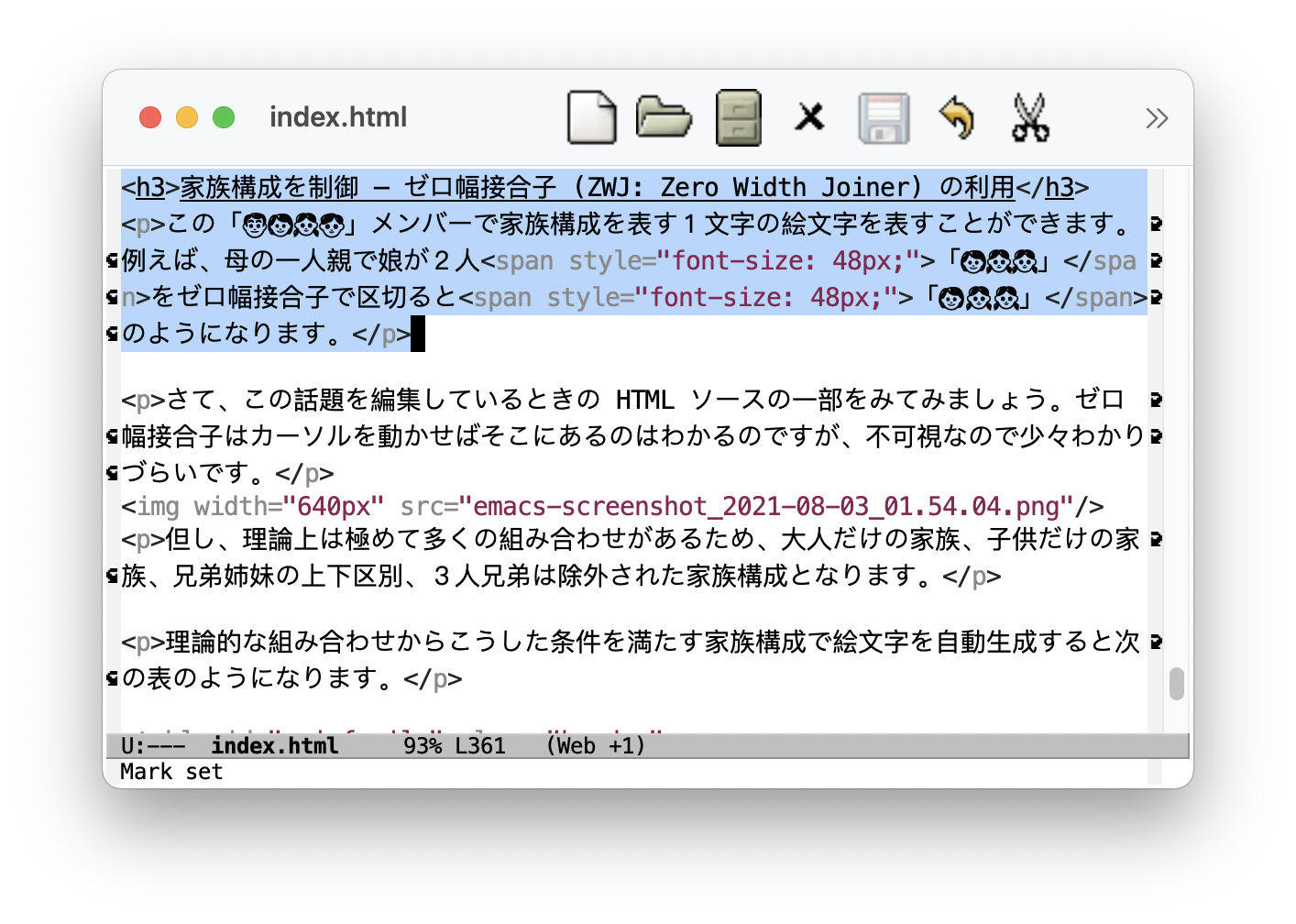
但し、理論上は極めて多くの組み合わせがあるため、執筆時点で絵文字として定義されているのは、大人だけの家族、子供だけの家族、兄弟姉妹の上下区別、3人以上の兄弟を除外した家族構成に限ります。
理論的な組み合わせからこうした条件を満たす家族構成で絵文字を自動生成すると次の表のようになります。
執筆時点でこれらの肌の色は制御できないようです。ちなみに、無性別の家族は唯一「👪」が単一のコードポイントで定義されています(日本の携帯電話の絵文字由来のコードポイントを無性別にしたわけです)。
日本の携帯電話の絵文字にカップルを表す絵文字があり、Unicode では女性と男性、男性同士、女性同士で手を繋ぐカップル「👫, 👬, 👭」が単一のコードポイントに定義されています。さらに、ハート&キスのカップルとハートのカップル「💏, 💑」も単一のコードポイントに定義されています。こちらは元々は男女の意だったのですが近頃はジェンダー・ニュートラルとされています。
よって、前者はジェンダー・ニュートラル版「🧑🤝🧑」が「🧑 + ZWJ + 🤝 + ZWJ + 🧑」、後者はジェンダー版「👩❤💋👨 👨❤💋👨 👩❤💋👩, 👩❤👨 👨❤👨 👩❤👩」が「🧑 + ZWJ + ❤ + ZWJ + 💋 + ZWJ + 🧑, 🧑 + ZWJ + ❤ + ZWJ + 🧑」による組み合わせで絵文字が定義されています。
しかも、いずれも単一のコードポイントが存在するにも関わらず男性、女性、無性別「👨, 👩, 🧑」を任意に代入しても一つの絵文字に構成されます。
さらに、これらは驚くべきことに、それぞれの人物の肌の色を制御できるのです(但し、手を繋ぐカップルの片方のみ「肌の色を指定なし」というのは未定義)。
さて、この話題を編集しているときの HTML ソースの一部をみてみましょう (スクリーンショットをクリックすると拡大)。
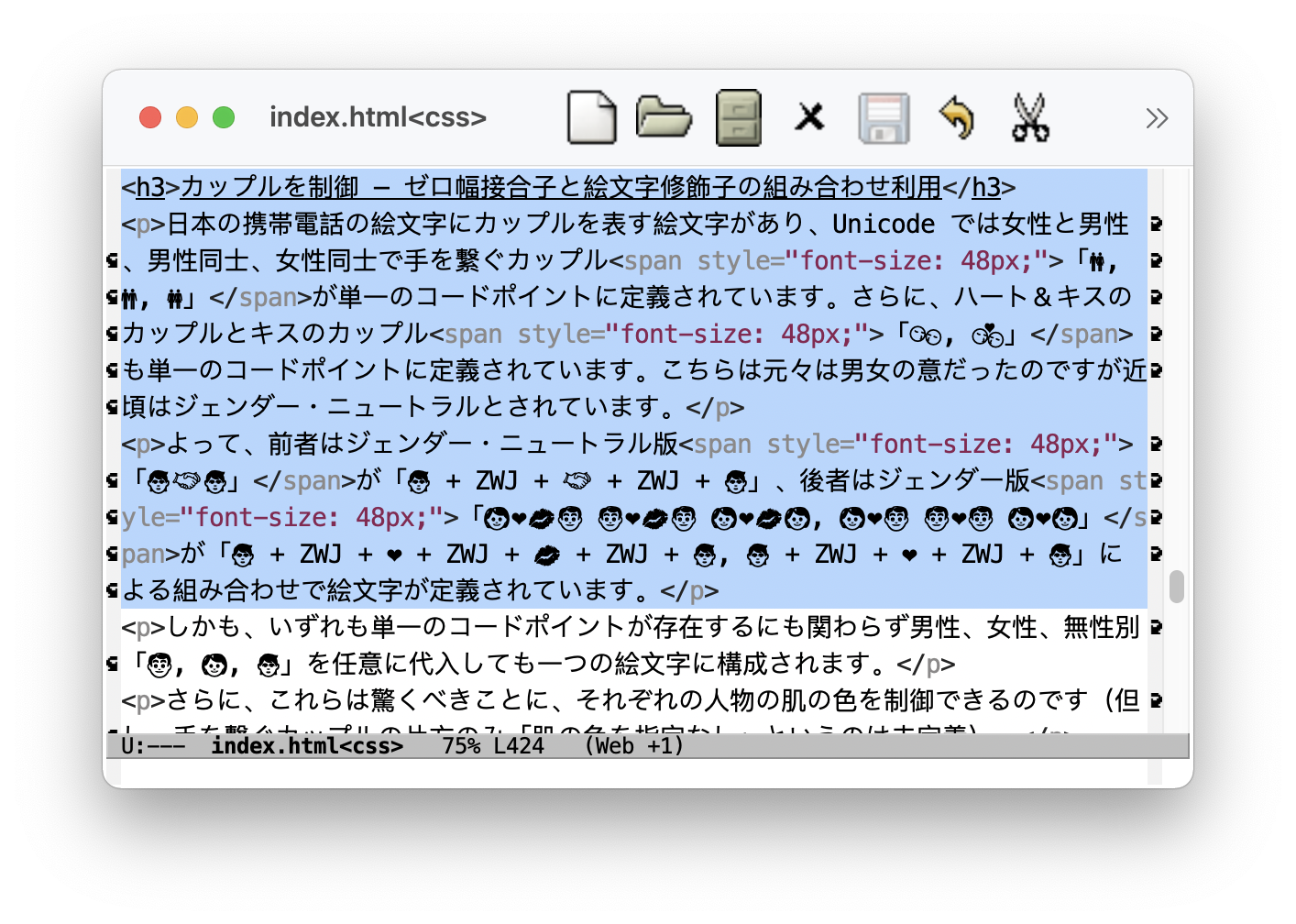
では、Javascript による表の自動生成ですべての組み合わせ (男性、女性、無性別)×(男性、女性、無性別)×(5または6種類の肌の色) を以上3種の着色絵文字を総覧します。
肌の色の絵文字修飾子の配列と男性、女性、無性別の配列のペアをそれぞれ組み合わせて (6×6 - 5×2)×4 = 26×4 または 6×6×4 = 36×4 の表になっています。
Safari と Firefox では問題なく着色絵文字が総覧できているのですが、執筆時点で Chrome, Edge だとカップルがなぜか「距離を置いて」います。その事実から推察できるのは、これらは中間処理的に「合字」で実現しているのでしょう。そして、Chrome らではその処理には未対応ということかと思われます。
少々技術的な話題となりますが、この「手を繋いだカップル」の Javascript による表の自動生成コードを以下に載せておきます (スクリーンショットをクリックすると拡大)。
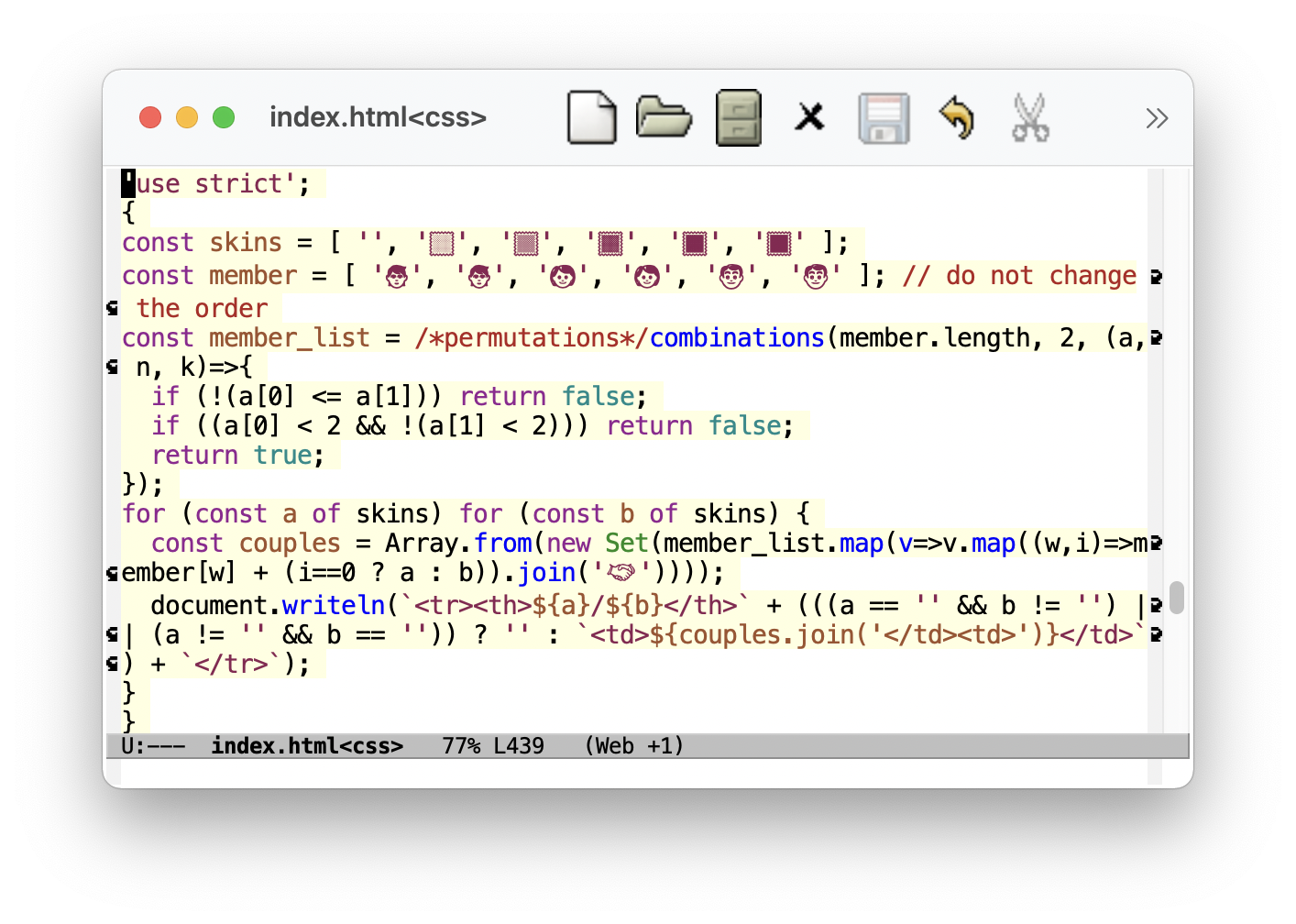
「🤝︎」の両端に編集可能なほぼ不可視の ZWJ が添えられています。
すべての絵文字の定義については Unicode.org の絵文字リスト及び絵文字修飾子シーケンスに網羅されています。
ここで、フォントの種類によってデザインや用途を伺い知るために、絵文字が存在するコード領域を画像にしておきます (フォールバックフォント機構がそのまま働いているので、未定義グリフなら別フォントのグリフが印字されています。)。
すなわち、上図のように絵文字が格納されている Unicode のコード領域を列挙しても、すべての絵文字を網羅できないということです。
20年ほど前、筆者は「睆」や「暲」という漢字を印字したくて所謂「補助漢字」に行き着いて、結局この漢字が当時公式な文字コード (euc-japan) では印刷に難があり、「目」偏に「完」、「日」偏に「章」を細く組み合わせて凌いだ記憶があります。マイクロソフトの CP932 や公式の補助漢字 (JIS X 0212) なら対応していたのですが、前者はベンダー依存の非公式ですし、後者は公式なのに対応しているシステムが少ないという問題がありました。
また、肉親の名前が戸籍上は「廣」(でも正確にはこれでもない)だけど「広」で構わないなどと言われ、計算機科学に対してなんとも釈然としない苛立ちもありました。現在でもそうですが、当時は情報交換用の文字と字体は完全に区別して考える必要があったのです。
時は過ぎて、今や多くの先人の尽力により、こうした日常的にはあまり使われない特に地名・人名などで使われる漢字を使うことが出来るようになって来ました。CJK 統合漢字によって一度は国際的に破茶滅茶になってしまった漢字ですが、色々な仕組みが整備されつつあり紆余曲折・混沌とはしながらも、IPA (情報処理推進機構)、そして、CITPC (文字情報技術促進協議会) によって行政で必要とされる漢字(筆者は「異体字」という言い方を好まず、康熙字典と異なる字体を異体とするのは全て正しいとは言えない)が相当揃っています。また、Adobe-Japan1 規格も印刷業界で必要とされてきた字体が独自の規格から Unicode へと公式なものへと昇格しました。
まずここでは興味本位で、異体字(というしかないですね、やはり)の種類が多い漢字を Unicode とフォント技術で HTML 上で印字してみたいと思います。眼がしばしばします。その方法は後述します。
おお!筆者の父の名の正確な漢字「廣󠄂」がありました。
但し、フォントが対応していないと上の表の異体字は意図したグリフにはなっていないと思います。また、文字情報技術促進協議会が配布する「IPAmj明朝フォント」と Adobe の「源ノ系」フォントとは(よく調べてませんが)異なっている気がします。よって、各種フォントを兎に角選べるようにしておきましたので、適宜試してみてください。
IVS ready と添えたフォントが筆者が執筆時点で確認した IVS 対応フォントです。
(注) テキストエリアにはフォントファミリ名を正確に入力する必要があります。英名と和名の両方をもつフォントにて和名の全角・半角(「MS 明朝 (空白のみ半角!)」など)に注意してください。
このような後述の「IVS による異体字」をもつ、すべての漢字を下表にまとめておきます。
閲覧環境の日本語フォントによりますが、それでも下表の異体字が全て揃っているなどという日本語フォントはありません。字体が変わっているのが見つけられれば「なるほど点が一つ多いだけか」などと感想をもっていただければよいと思います。そして、上述と同じくフォントファミリ名をそこのセレクタで変えてみることもお勧めします。
本稿はウェブ向けでウェブフォントを使う予定もなく、読者の閲覧状況が筆者のそれと等しい保証などなくて些か勇足で恐縮なのですが、ここでは一つの異体字を取り上げて解説します。また、オペレーティングシステムの入力ソースが対応、かつ、異体字切り替え対応フォントが指定してあれば、異体字を選んで入力することは出来る[1]はずですので、各フォントベンダ等が使い方の説明をしていますし、そちらに譲ることにします。さらに、JIS2004 以前の異体字については補遺 1. で触れましたので、そちらをご覧ください。
「龍」の異体字の一つ、最終角が縦の「龍󠄁」、及び、「玉」の異体字の一つ、最終点がない「玉󠄂」を取り上げます。
本稿は Emacs での実現方法を紹介するものなので、その解説をします。ここまで読んだ方にとっては簡単なことだと思いますが、改めて説明します。
一つ目、ベースとなる「龍」の字に異体字セレクタ VS18 (U+E0101) を付記すると(フォントが対応していれば)「龍󠄁」のようになります。
同様に、ベースとなる「玉」の字に異体字セレクタ VS19 (U+E0102) を付記すると(フォントが対応していれば)「玉󠄂」のようになります。
さて、この話題を編集しているときの HTML ソースの一部をみてみましょう (スクリーンショットをクリックすると拡大)。
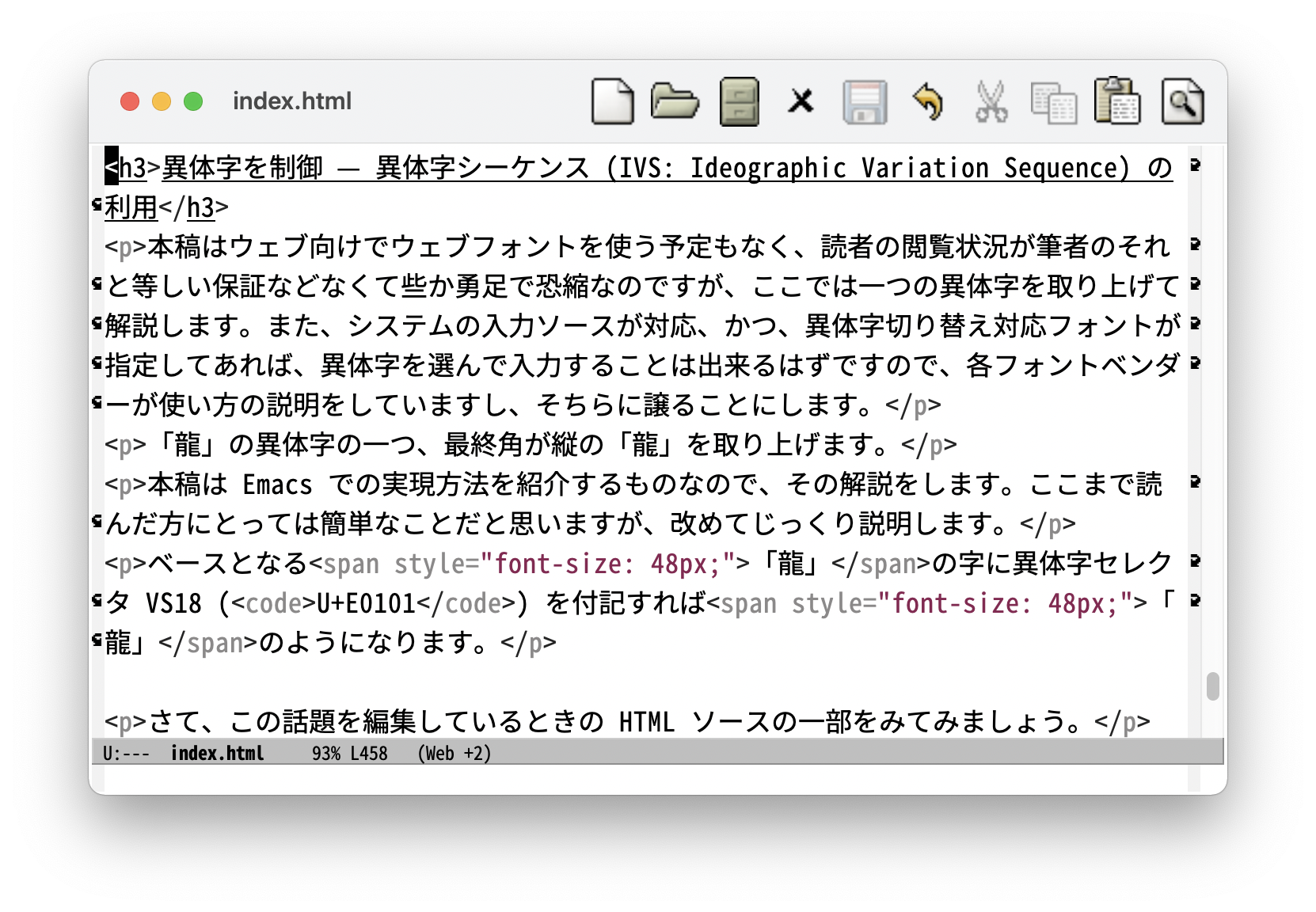
上述の操作をすると Emacs では字体が変わります。VS が可視化されるということではないようですが、VS があるものとしてカーソルは移動できるので編集は可能です。
事は絵文字と違って、人名に関わることになると字体が間違ってたとしたら失礼に当たるかもしれませんし、しかも、あたかも「間違い探し」のように漢字の部品をよ〜く見ないと違いが判らないのが漢字の異体字なので、最小限の注意は払うようにしましょう。
ちなみに、象形文字の異体字の一次情報源は unicode.org/ivd/data/ になります。
残りの注意事項としては、異体字切り替えに対応したフォントであることが必須ですので、筆者が把握しているフォントを紹介しておきます。
筆者がかつてフォントで苦労した時代を思えば、現在、大変羨ましい恵まれた状況にあります。そして、頼もしいのが IPA フォントから始まったオープンソースフォント文化から有志がそれらの派生オープンソースフォントを整備しつつあることです。
日本における漢字文化を大切にする上でも、これらのオープンソースをはじめ異体字に対応したリッチな日本語フォントは極めて重要に思います。
本稿では JIS X 0213:2004 以降の「すすんだ異体字」を取り扱った為、従前の異体字と呼ばれている JIS X 0208:1990 (JIS 第一水準・第二水準) や JIS X 0212:1990 (JIS 補助漢字) までに変更されたり追加されたりした異体字については、特に説明はしておりませんでした。というのも、オペレーティングシステムの入力ソースで特に気にせずに異体字が選べるはずだからです。
しかし、JIS X 0213:2004 (JIS2004) は比較的新しいので、レガシーなフォントを使っていると JIS2004 以前の漢字しか印字できないことも考えられますので、以下に変更があった漢字、及び、追加された漢字を記しておきます。
読者の閲覧環境で意図した通りに漢字が見えているなら、適切なモダンなフォントが備わっている証左と考えてよろしいと思います。
変更は主に JIS83 までで主流だった拡張新字体から康熙字典体への回帰であることがわかるかと思います。変更前が誤りというわけではなく、あくまで組版における字体であるので、書字に適しているのは拡張新字体であると考えてよろしいと思います。
以下は、追加なのに、それに対応する従来の漢字というのは、いずれにせよ JIS78 にはあったような異体字を要したが、Unicode にそれが既に登録されていたために例示体の変更を避けざるを得なかった漢字、ということになります。
本稿の主題の Emacs のようなエディタに話題を戻せば、同一コードポイントに割り当てられた例示体の切り替えは不可能ですので、見た目の上でフォントを変えてそれが正しく見えていたとしても、情報交換にそれが保持されるかはまったく別の問題ですので注意してください。例えば、この文書は HTML で執筆しているのでカスケードスタイルシート (CSS: Cascading Style Sheets) の機能である font-variant-east-asian: jis90; を使って JIS90 の漢字を印字しています。
先の GNU プロジェクトのオープンソースフォント Unifont のサイトに Unicode 主要面の収録グリフ一覧がわかる画像を用意してくれています (第0面、第1面)。Unicode の広大さを理解できますので一度ざっとでも見てみるとよいと思います。しかし、他面がなかったので筆者が同等のものを以下に制作しておきました。






U+0000〜FFFF (クリックして拡大、さらにクリックして拡大)





U+10000〜1FFFF (クリックして拡大、さらにクリックして拡大)


U+20000〜2FFFF (クリックして拡大、さらにクリックして拡大)

U+30000〜3FFFF (クリックして拡大、さらにクリックして拡大)U+E0000〜EFFFFU+F0000〜FFFFFU+100000〜10FFFFちなみに、第三漢字面で疎らに定義されている漢字をいくつかブラウザで表示してみると、「𰜩」U+30729、「𱁬」U+3106C、「𰻝」U+30EDD、「𰻞」U+30EDE となります。閲覧環境によって視認できているでしょうか。
BMP 内の2つの領域「上位サロゲート」U+D800〜D87F と「下位サロゲート」U+DC00〜DFFF を使って BMP 以外の面を割り当てています。これをサロゲートペア(代用対)と呼びます。よって、U+FFFF より大きなコードポイント2バイトはサロゲートペア2×2バイトで表現されていることを知っておく必要があるときもあります。少なくともプログラマは知っておかないと文字列処理でトラブルに見舞われるかもしれません。
そして、そのように表現された2バイト毎の列をさらに 7 ビット領域は ASCII コード互換となる「UTF-8」と呼ばれる文字エンコーディング方式によって符号化され、ファイルに保存したり通信に利用されたりします。7 ビットセーフな「UTF-7」と呼ばれる文字エンコーディング方式は(必要となるときも稀にあるものの)、電子メール用途に考案されましたが事実上使われることがなくメールでは非推奨となっています。
Copyright © 2021 Taiji Yamada{kind=link}
{kind=link}